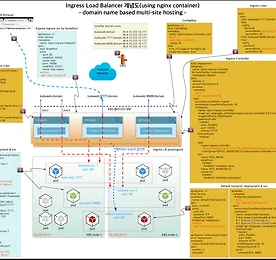
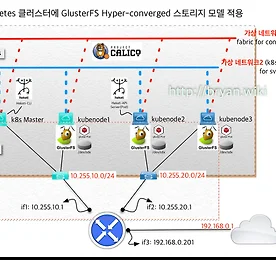
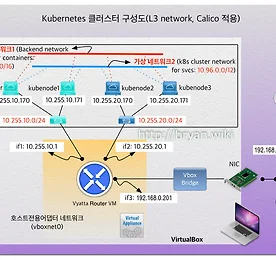
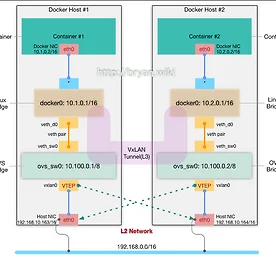
Technical 썸네일형 리스트형 [Kubernetes] Traefik v2와 cert-manager 를 이용한 secure service 구현 GCP, AWS와 같은 Public cloud나 On-premise 에서도, 외부에 secure web 서비스를 제공하기 위해 http entrypoint에 대해 유효한 SSL 인증키를 적용하기 위해서는 많은 번거로운 작업 과정을 거쳐야 한다. 그 방법도 여러 가지가 존재하겠지만 여기서는 Kubernetes의 장점을 살려, 간단한 설정과 수작업이 최소화 된 간편 버전의 솔루션을 직접 구현해 보고 정리한 문서를, 따라하기 버전으로 소개하려 한다. Traefik ingress 의 entrypoint에 대해 Let's Encrypt 로부터 유효(정식) 인증키를 적용해 주는 cert-manager(Jetstack 버전) 를 활용한 방법을 아래에 정리해 둔다. Cert-manager 활용 - jetstack/ce.. 더보기 Amazon Route53, Google cloud DNS 를 활용한 kubernetes service DNS 자동화 (3/3) 3. Google cloud DNS managed zone과 External DNS로 kubernetes service 연결하기 지난 2개의 글(https://bryan.wiki/305, https://bryan.wiki/306) 에 이어서, 이번에는 Google cloud DNS에 hosted-zone을 생성하여 Local kubernetes 의 external-dns를 통해 deploy 되는 service를 연결해 보자. 시리즈 처음 글에서 Google cloud DNS 측에 생성한 gcloud.kube.click 도메인을 사용한다. Google cloud DNS project의 managed zone 확인 GCP console 좌측 메뉴에서 Network services > Cloud DNS > Z.. 더보기 Amazon Route53, Google cloud DNS 를 활용한 kubernetes service DNS 자동화 (2/3) 2. AWS Route53 hosted-zone(호스팅영역) 과 External DNS로 kubernetes service 연결하기 지난 글(https://bryan.wiki/305) 에 이어서, 이번에는 Route53에 hosted-zone을 생성하여 Local kubernetes 의 external-dns를 통해 deploy 되는 service를 연결해 보고자 한다 Route53 hosted-zone 만들기 Aws console UI에서 Route53 > 호스팅 영역 > 호스팅 영역 생성' 을 통해서도 동일한 결과를 볼 수 있다 $ aws route53 create-hosted-zone --name route53.kube.click --caller-reference this-hosted-zone-is.. 더보기 Amazon Route53, Google cloud DNS 를 활용한 kubernetes service DNS 자동화 (1/3) 1. AWS Route53 도메인을 parent domain으로 Google cloud DNS sub-domain 등록 활용하기 이번에는 하나의 목표를 위한 3개의 글로 이루어진 시리즈물을 포스팅을 해 보려 한다. 최종 목표는 Public cloud의 managed DNS 서비스를 통해, 특정 도메인(FQDN, 여기서는 본인이 보유 중인 Route53 managed 도메인 중 kube.click 이라는 도메인의 subdomain 을 route53.kube.click 또는 gcloud.kube.click로 만들어서 사용)의 서브도메인이 자동으로 만들어지고, 해당 도메인을 통해 Kubernetes service로 외부에서 접속 가능하도록 구성해 보는 것이다. 즉, kubernetes service(또는 in.. 더보기 Setting GOPATH & Basic golang 개발 Setting GOPATH & Basic golang 개발 Refer 1: SettingGOPATH · golang/go Wiki · GitHub Refer 2: Go 코드를 작성하는 방법 · golang-kr/golang-doc Wiki · GitHub 특별히 공유 목적을 위해 만든 글은 아니다. 그냥 예전에 했던 설정 방식이 기억 나지 않아 구글링을 하다가 리프레시해둬야 겠다는 단순한 의도로 끄적 거려 둠. 그러나 누군가에겐 조금의 도움이 되었기를 ... Zsh Add to ~/.zshrc export GOPATH=$HOME/go source it source ~/.zshrc Bash Add to ~/.bash_profile export GOPATH=$HOME/go source it source ~/.. 더보기 MacOS iterm2 + zsh 에서 cursor 이동을 편하게 MacOS 기본 터미널 bash command-line ⌥ + ← 또는 ⌥ + → : 커서를 왼쪽 단어 또는 오른쪽 단어로 ⌘ + ← 또는 ⌘ + → : 커서를 start 또는 end of line 으로 zsh 의 경우 ESC B 또는 ESC F : 커서를 왼쪽 또는 오른쪽 단어로 이동(불편하기 짝이 없음) ⌃ + a 또는 ⌃ + e : 커서를 start 또는 end of line 으로 bash 기본 터미널, zsh 각각에서 별도 설정을 하지 않았을 경우 위의 스타일 대로 커서가 이동 된다. 본인은 MacOS Catalina에서 'Oh My Zsh' 와 iterm2 를 사용중인데, 아무래도 ⌥ + ← 또는 ⌘ + ← 방식에 익숙해져 있어서 다음의 방법대로 설정 사용중이다. zsh에서 MacOS 기본 ba.. 더보기 [Kubernetes StatefulSet] Mariadb Galera Cluster with etcd(3/5) 이번 포스팅에서는 Statefulset 형태로 구현이 가능한 대표적인 클러스터인 Galera Cluster를 다루어 볼 것이다. 그 중에서도 Galera Cluster의 각 노드(Pod)의 상태를 etcd 데이터 스토어에 기록하고 사용할 수 있도록 etcd cluster를 동시에 활용하는 방식을 적용해 보려 한다. 주요 참조 기술 및 블로그는 글 말미의 Reference 를 참조하기 바란다. 앞서의 포스팅들과는 다르게 여기서는 Kubernetes 의 현 시점의 최신 버전인 1.11.3 을 활용하였다. Mariadb Galera Cluster 구현을 위한 준비와 개념도 [Prerequisites] Running k8s cluster with persistent storage(glusterfs or nfs .. 더보기 [Kubernetes StatefulSet] Mongodb Replicaset by StatefulSet(2/5) Mongodb Replicaset을 구현하는 방법은 여러 가지(sidecar, init-container 방식 등)이 있지만, 여기서는 docker.io의 mongo 3.4 ~ mongo:3.7 까지의 범용 이미지를 사용한 Replicaset 구현 방법을 다루어 보고자 한다. Mongodb Replicaset 구현 & 기능 검증 [Prerequisites] Running k8s cluster with persistent storage(glusterfs class, etc.)Tested kubernetes version: 1.9.x, 1.11.x [Deployment resources - mongodb-service.yaml] # Service/endpoint for load balancing the cl.. 더보기 [Kubernetes StatefulSet] 개요 & Nginx Web Cluster(1/5) Kubernetes의 컨테이너 오케스트레이션을 이용한 어플리케이션의 구현 방식 또는 기술에서 중요하게 다뤄야 하는 것 중 하나가 StatefulSet 이다. 개념을 명확히 해야 하는 점에서, 아래의 두 가지 개념을 염두에 두고 상황에 따라 잘 활용해야 할 필요가 있어서 본 시리즈를 기획하였다. Stateless ApplicationWeb front-end 와 같이 디스크에 중요한 데이터가 없는 것들필요한 만큼의 여러 개의 똑같은 컨테이너를 시작/종료할 수 있는 것들Ephemeral 특성 - 컨테이너가 죽으면 내부에 보관중인 데이터는 사라짐Instance 별의 특별한 데이터가 없을 것 Stateful ApplicationContainer-specific 특성(주로 호스트/도메인명, 드물게는 IP 주소)암호.. 더보기 [GitLab] Server-Side Hook 스크립트(pre-receive) 활용 개요 GitLab 을 위한 Custom Hook은 다음의 3 가지 중 하나로 구현된다(Community Edition 기준). pre-receive: Git 서버가 클라이언트로부터 Push 요청을 받은 즉시 수행되며, 스크립트에서 non-zero 값을 return 하면 Push 요청은 reject 된다. Push 요청에 대한 값은 스크립트 내에서 stdin 스트림 값을 읽어서 사용 가능하다update: pre-receive 와 유사하지만, pre-receive 는 한 번의 Push에 대해 단 한 번 수행되며, update는 각각의 Branch 마다 triggering 되는 점이 다르다. 따라서 여러 Branch에 Push 를 수행하게 되면 특정한 브랜치에 대해서만 reject 되게 처리되게 하고 싶을 떄.. 더보기 [Kubernetes - CI/CD] Customized Jenkins 제작과 활용 - 2/2 전편에 이어지는 내용으로, 이번에는 예제 프로젝트인 hugo-app 을 대상으로 개발~배포~실행까지 Pipeline을 구성하여 CI/CD 과정을 구현해 보자 Jenkins-leader 서비스 기동 새로운 프로젝트를 시작할 때, 전용의 Jenkins 빌더 셋을 만드는 과정에 해당기존에 제작/테스트 했던 jenkins 서비스 환경을 tear-down 하고 Custom Jenkins 빌더로 새로 시작[root@kubemaster 00-jenkins-custom-image]# kubectl delete -f 02-jenkins-dep-svc.yaml -n ns-jenkins[root@kubemaster 00-jenkins-custom-image]# kubectl delete -f 01-jenkins-leader.. 더보기 [Kubernetes - CI/CD] Customized Jenkins 제작과 활용 - 1/2 Kubernetes 를 활용하여 CI/CD를 구현하는 방법은 여러 가지가 있다. 이번 시리즈는 커스텀 Jenkins 이미지를 사용한 컨테이너 Application 빌드 배포 자동화를 구현해 보고자 한다. 본 글은 그 첫 번 째로, 커스텀 Jenkins 이미지를 제작, 테스트 빌드를 통해 CI/CD가 정상적으로 작동하는지를 확인하는 내용이다. PrerequisitesKubernetes 1.8~1.9.x 가 설치되고 정상 작동 할 것Application 소스 저장소로 사용할 github 계정 준비Persistent Volume으로 사용할 Storage는 Heketi-API로 연동된 Glusterfs(http://bryan.wiki/286 참조)Jenkins 빌드 작업을 위한 네임스페이스틑 ns-jenkins.. 더보기 [Kubernetes Cluster 관리] 클러스터 컨텍스트 변경과 kubectl을 통한 multi-cluster 접속 Kubernetes 를 사용하다 보면 서로 분리된 환경에 설치된 여러 클러스터에 번갈아 접속해야 할 경우가 종종 발생한다. 예를 들어 한 쪽은 개발&테스트, 다른 한 쪽은 실제 서비스 클러스터 환경, 이런 식이다. 접속 터미널을 따로 띄워서 간편히 사용하는 경우가 많겠지만, 필요에 따라 하나의 kubectl 클라이언트로 서로 다른 클러스터에 접속할 수 있도록 설정하는 방법을 정리한다(K8s 1.6.x~1.8.x 기준). 클러스터 이름과 관리자 이름 변경 Kubernetes 를 구글 repo를 통해 기본 설치로 진행하면, kubectl을 통한 클러스터 접속용 설정 파일(yaml 형식)은 위의 캡처 이미지와 같은 모양으로 나타나게 된다(root 유저일 경우 KUBECONFIG 환경변수의 값은 '/root/... 더보기 [Kubernetes RBAC] API 연결로 확인해 보는 RBAC 설정 방법 RBAC(Role Based Access Control). 우리 말로는 "역할 기반 접근 제어" 라고들 표현하지만 사실, '역할' 보다는 '권한' 이라고 이해하는 것이 더 뜻이 잘 통한다. Kubernetes 1.6 버전부터 kubeadm 을 통한 Bootstrap 방식의 설치가 도입되면서 RBAC의 기본 설정이 이루어지게 되어 있는대, 구글링을 통해 접해 본 예전 문서들에서는 curl 을 통해 쉽게 접근 되던 API 들이, 권한이 없다는 메시지를 뿌리며 실패되는 모습을 자주 보게 되면서, 이 부분에 대해 직접 실험하고 규명해 보고자 하는 생각이 들기 시작했다. Kubeadm 의 bootstrapping 에 의해 설정된 기본 RBAC 확인 먼저 마스터에서 아래의 명령을 실행해 보자. # APISERVER.. 더보기 Split Brain - MariaDB Galera Cluster Case Split Brain 은 Clustering 또는 다중 노드/스토리지 구성의 각종 솔루션들(주로 고가용성과 부하분산, 즉 HA 용도), 예를 들어 Redis-Sentinel, MariaDB Galera Cluster, GlusterFS 파일 분산복제 설정, Oracle RAC, vSphere HA 구성 등에서 중요한 장애 유발 요인이며, Production 환경에서 점검해야 할 중요한 아키텍처적 회피 대상 항목에 해당한다. 1. Split Brain 이 도대체 무엇일까? 문자 그대로 "뇌가 양쪽으로 분단 된" 모양 또는 상황 그자체를 표현한다. IT와 무관한 비유를 해 보자면, 머리 둘 달린 용이 왼쪽으로 갈지 오른쪽으로 갈지 몰라서 갈팡질팡하는 형국이라고 할 수도 있겠다. 실제로 인간의 뇌는 좌뇌와 우.. 더보기 Curl로 새로운 GitHub 프로젝트(repository) 쉽게 생성하기 GitHub 에 새로운 repository를 생성할 때 어떻게 하시나요? 주로 github 접속/로그인-New Repository 클릭-이름입력-Create Repository 클릭-로컬 git 디렉토리 생성-git init-git add-commit-push 과정을 통해서 진행할텐데, 과정 자체가 어려운 건 아니지만 번거로운 점이 적지 않습니다. 이 과정을 간단한 스크립트를 만들어서 진행하면 어떨까요? 준비사항GitHub Account: github.com 에 가입(It's free!)Git client와 curl이 설치된 linux box 스크립트 작성 & 실행 여기서 개발자의 작업 PC는 CentOs/RedHat linux 박스로 하고, 우선 Github에 올릴 소스 작업 디렉토리가 필요하겠지요. .. 더보기 [Kubernetes ingress part-1] Nginx ingress 구현과 사용 방법 K8s(쿠버네티스) 클러스터 내에 구현된 Application을 외부로 노출하여 서비스할 경우에 주로 Nginx의 LB 기능을 이용한 Ingress Load Balancer를 사용하게 된다. 기본적으로 제공되는 이러한 Nginx 컨테이너 방식 외에도 Haproxy, Traefik Ingress등의 3rd party 솔루션들이 존재하는데, 다음 part-2 에서는 최근 hot하게 뜨고 있는 Traefik Ingress를 사용한 구현을 다룰 예정이다. 필요 요소와 서비스 구성 Kubernetes Cluster(Local cluster, minikube or dind-cluster not in the cloud like AWS or GCP)Backend Service(like web or specific ap.. 더보기 [Kubernetes, Docker] Go 언어로 Tiny Web Server 만들고 docker hub에 공유하기 최근 Containter Orchestration 관련된 작업을 진행하고 있는데, 초기 테스트 수준의 클러스터 구성이나 솔루션의 기능 확인/검증시에 사용할 Web Server 기능을 하는 컨테이너를 주로 nginx 베이스 이미지를 사용 하고 있는데, 특정 용도에 맞게 html 파일을 수정해 주어야 하는 등 귀찮은 일 들이 많다. 도커 이미지 크기도 100MB 이상이어서 생각보다 크고... 그래서 생각한 것이 "내 맘대로 주무를 수 있는 컨테이너형 작은 웹서버" 를 만들고 언제든 사용할 수 있게 해 보자는 생각이 들었다. 어떻게 하면 작고 가벼운 웹서버를 만들고 필요할 때 언제든 사용할 수 있는가? 베이스 이미지가 작아야 하므로 busybox 이미지를 쓴다(1 MB +) 웹서버의 하위 페이지에 따라 특정 .. 더보기 [Kubernetes] Hyper-converged GlusterFs integration with Heketi -4/4 Kubernetes Cluster 에서 사용할 스토리지로 외부의 Glusterfs 를 Dynamic Provisioning 스토리지로 사용할 경우에 대한 구축 방법에 대한 앞선 포스팅(http://bryan.wiki/283)에 더하여, 또 다른 Dynamic Provisioning 솔루션이 대해 정리해 보겠다. 즉, 본 시리즈(1~3)의 현재까지의 구축 환경을 그대로 활용하여, 추가로 Glusterfs를 컨테이너 방식으로 각 Minion 의 Pod(DaemonSet)에 위치 시켜 각 Minion 에 추가장착된 HDD(그림에서는 /dev/sdx 로 표시)를 glusterfs의 분산 디스크로 사용, Heketi API 를 통한 kubernetes 와의 통합된 환경을 구축하고 실제로 PV를 만들고 테스트해 보.. 더보기 [Kubernetes] 1.7.x~1.9.x, kubeadm 으로 L3 네트워크 기반 Cluster 구성(with Calico CNI)-3/4 4개의 시리즈 중 세 번 째로, 이번에는 2017/08 최종 버전인 Kubernetes 1.7.4 의 kubeadm 을 통한 클러스터 구축을 서로 다른 네트워크가 L3로 연결된 환경에서 구현하는 과정과 방법에 대해 알아 보고, 기본적 테스트와 검증을 진행하는 내용으로 마무리 하고자 한다.* 1.8.x 버전 릴리즈 시 변경 사항 추가(2017.10.16. ... #1.8.x, 붉은 글씨로 표시). : https://github.com/kubernetes/kubernetes/issues/53333 참고)* 1.9.x 버전 릴리즈 시 변경 사항 추가(2017.12.26. ... #1.9.x, 붉은 글씨로 표시). 각 노드에 해당하는 서버의 준비 Master: CentOS 7.3(1611), CPU 2, Mem.. 더보기 [Kubernetes] CentOS 7.3 으로 Kubernetes Cluster 구성(노드 추가하기)-2/4 전편(http://bryan.wiki/281)에 이어서, 이번에는 기존 k8s 클러스터에 새로운 워커 노드를 추가하는 방법에 대해 알아 보자. 클러스터의 환경 구성은 전편과 동일하다. 새로운(3 번째) 노드의 준비 * Minion 3: CPU 1, Memory 1.2GB, IP 10.255.10.183 기존 노드와 동일/유사 스펙과 설정으로 구성해 나간다 추가 Minion 노드 시간동기화 설정 [root@kubenode3 ~]# yum -y install --enablerepo=virt7-docker-common-release kubernetes etcd flannel wget git[root@kubenode3 ~]# yum update -y[root@kubenode3 ~]# vi /etc/chrony... 더보기 [GlusterFS & Kubernetes] External Gluster PV with Heketi CLI/Rest API Kubernetes 또는 OpenShift 로 PaaS 를 구축할 경우에, 사용자 환경에 대응하는 인프라 측의 2개 부문의 솔루션을 반드시 고민해야 하는데 그중 하나가 Persistent Storage 에 대한 솔루션이다(다른 하나는 Overlay Network 을 위한 터널링 솔루션/Fabric 이 되겠다). 대개는 NFS 와 같은 일반적인 스토리지 모델을 적용하여 Persistent Volume을 일정 갯수 이상 만들어 놓고 사용/반납하는 식으로 사용(Static Provisioning)할 것 같은데, GlusterFS를 스토리지로 사용하고 각 워커노드에서 Native GlusterFS Client 를 활용한다면, Auto-healing 과 분산 파일 스토리지의 장점을 살리면서 스토리지 공간도 동적으.. 더보기 [VirtualBox] CentOS 7.3 VM template 이미지 제작 & 활용하기 특정 작업을 수행하기 위해 VirtualBox 내에 동일한 OS로 비슷한 스펙을 가진 VM을 여러 개 만들어야 할 일이 있을 것이다. 매번 OS를 설치하고 기본 패키지를 다운로드, 설치/설정을 반복하는 일이 번거롭고 시간을 뻇기는 부담으로 느껴진다면 이 방법을 한 번 써 봐도 좋겠다는 생각에서 정리해 둔다. 사전 준비 * VirtualBox가 설치된 호스트 머신* template에 설치할 OS 이미지(ISO) 파일 준비, 여기서는 CentOS 7.3(1611) Minimal ISO VirtualBox VM template 제작 1. 적당한 스펙의 VM(CPU1, Memory 1GB)을 새로 만들기가상하드디스크는 VMDK 또는 VDI 형식을 선택 2. 저장소의 CDROM에 CentOS 7.3 ISO 파일 .. 더보기 [Kubernetes] CentOS 7.3 으로 Kubernetes Cluster 구성(with Flannel)-1/4 Kubernetes 를 CentOS 7 에서 설치하는 방법을 정리해 둔다. 3개의 VM을 준비하고, Mater 하나와 두 개의 Minion(Slave 또는 worker node, 그냥 노드라고도 한다) 구성의 Custer를 구현하되, 네트워크 백엔드 솔루션(Network Fabric)은 CoreOS 에서 기본 채택하고 있는 Flannel을 사용하여 서로 다른 호스트(Worker node, Minion)의 컨테이너간 터널링을 통한 연결이 가능하게 설정할 것이다(총 4개의 시리즈로, 마지막 포스팅에서는 Kubeadm 을 통해, BGP 라우팅이 가능한 Calico Network를 적용한 Kubernetes 클러스터를 구현해볼 예정이다) Docker Engine과 함께 Kubernetes 를 설치하는 방법은, .. 더보기 Open vSwitch, VxLAN을 이용한 분산 Docker 컨테이너 간의 네트워크 연결(2/2) - 전편에 이어서 - 이번에는 아래 그림에서와 같이 L3 network로 연결된 Docker 호스트간 L2 통신 방법(2)에 대해 다룬다. 네트워크가 다른 2개의 호스트 사이에 인터넷이 있든, 여러 개의 라우터가 존재하든, 호스트간의 연결이 가능하다면 이 방법을 쓸 수 있다. 예를 들어 아마존 AWS의 가상머신과 사무실의 인터넷이 연결된 Docker 호스트 내부의 Docker 사이의 연결도 물론 가능할 것이다. 사전 준비라우터로 연결된 서로 다른 네트워크를 가지는 Docker Host(VM) 2대Docker Host #1: CentOS 7.3 Minimal Server(1611 ver), 10.255.20.10/24Docker Host #2: CentOS 7.3 Minimal Server(1611 ver.. 더보기 Open vSwitch, VxLAN을 이용한 분산 Docker 컨테이너 간의 네트워크 연결(1/2) 제목이 다소 길지만 앞으로 2회에 걸쳐서 정리할 내용은 Open vSwitch의 VxLAN 터널링을 이용하여 L2 network로 연결된 Docker 호스트의 Docker 컨테이너간 L3 통신 방법(1)과, L3 network로 연결된 Docker 호스트간 L2 통신 방법(2)에 대해 다루고자 한다. 본 1편에서 다루고자 하는 내용을 그림으로 나타내면 다음 그림과 같다. 도커/컨테이너에 대한 기본적인 개념 설명은 여기서는 다루지 않으며, 이후에 도커의 네트워크에 대해 간략히 따로 다룰 예정이다. 그림을 보면, 2개의 호스트가 Flat한 L2 Network로 연결되어 있고(SDN: Software-Defined-Network 개념으로 보면 Underlay) 각각의 호스트 내에 Docker Container.. 더보기 [Open vSwitch] Centos 7.x에 openvswitch 를 설치하는 2가지 방법 Open vSwitch는 SDN을 구현하는 대표적 오픈소스 기술 중의 하나이다. Open vSwitch는 분산된 노드들간의 가상 터널을 구현하는 3가지 방법(GRE, VxLAN, IPSec)을 모두 지원하는데, 본 편은 다음에 이어질 포스팅에서 다룰 VxLAN에 대한 사전 준비 과정에 해당한다고 할 수 있다. 대상 OS는 CentOS 7.x 로 하고, Open vSwitch 를 설치하는 방법은 크게 3가지 정도를 생각해 볼 수 있겠다. 소스를 빌드하거나 RPM 빌드 또는 레드햇의 Epel 레포지터리를 통해 yum 으로 설치하는 방법이 있다. 여기서는 뒤의 2가지를 다뤄두도록 한다(자세한 설명은 생략하고 필수적으로 수행되는 script 위주로 note 함). 이미지 출처: openvswitch.org RP.. 더보기 [OpenShift v3 #3] Origin 3-node, CentOS 7 기반 3노드 설치, 사용 방법(3/3) 2회(#2/3) 에서 이어지는 내용이다 GitHub 를 사용한 개발과정 맛보기 #2 - WordPress Sample & MySQL(PHP)이번에는 OpenShift GUI Console 이 아닌 명령어 방식으로 oc(OpenShift Client)를 사용해 보겠다. Master Node로 ssh 로그인을 하고 새로운 프로젝트를 생성한다. OpenShift Console에서 실시간으로 확인 가능하다 GitHub.com의 Wordpress project URL(https://github.com/DragOnMe/WordPress.git)을 복사한다 oc 명령으로 php:latest 도커이미지와 WordPress 소스 repository를 지정하여 새로운 App 서비스를 프로젝트에 추가한다. 진행 상황은 텍스.. 더보기 VirtualBox 에 Vyatta 라우터로 VM 가상 네트워크 구성하기 노트북에 서로 다른 사설IP 대역(노트북의 랜카드와 동일한 브리징 네트워크의 IP가 아닌, 내부 사설 네트워크)로 가상네트워크를 구성해서 VM을 만들 경우가 있다. 이 경우 대개 고정IP와 함께 고정된 default gateway를 설정하게 되는데, 사무실과 집을 오가다 보면 매번 VM들의 default gateway를 변경해 주어야 한다. 이런 번거로움을 피하기 위해 VirtualBox 내에 Vyatta Router VM을 만들고, 각 VM들의 사설 IP대역에 맞는 interface(eth1, eth2, eth3, ...)를 각각 설정한 다음, VM에서는 Vyatta Router의 interface IP를 default gateway 로 설정해 둔다. 물론 Vyatta Router의 eth0는 인터넷이.. 더보기 [OpenShift v3 #2] Origin 3-node, CentOS 7 기반 3노드 설치, 사용 방법(2/3) 지난 회에서 OpenShift Origin v3의 단일서버 구성 설치와 간단한 사용법을 정리하였다, 이번 회에서는 3-노드 구성의 OpenShift v3 설치 과정과와 Kubernetes, OpenShift console 및 CLI를 통한 Orchestration과 몇가지의 Use Case를 정리해 두고자 한다(이 글을 마지막으로 업데이트하는 시점에 OpenShift 릴리즈가 1.5.0으로 바뀌었다. 아래 설정 파일에서 v1.5.0으로 표시된 부분 참고=>1.5.0에 버그가 아직 많아 보이고, 결정적으로 1.5.1이 나온 시점에 docker 기반 설치에 오류가 발생하여 1.4.1 버전 기준으로 긴급히 되돌림 2017-05-27). 사전 설정(Pre-requisites)서버 구성(권장 최소 스펙) - OS.. 더보기 이전 1 2 3 4 5 다음