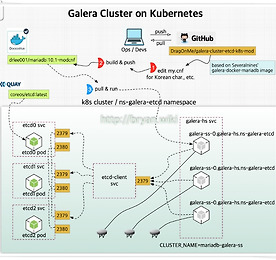
k8s 썸네일형 리스트형 [Kubernetes StatefulSet] Mariadb Galera Cluster with etcd(3/5) 이번 포스팅에서는 Statefulset 형태로 구현이 가능한 대표적인 클러스터인 Galera Cluster를 다루어 볼 것이다. 그 중에서도 Galera Cluster의 각 노드(Pod)의 상태를 etcd 데이터 스토어에 기록하고 사용할 수 있도록 etcd cluster를 동시에 활용하는 방식을 적용해 보려 한다. 주요 참조 기술 및 블로그는 글 말미의 Reference 를 참조하기 바란다. 앞서의 포스팅들과는 다르게 여기서는 Kubernetes 의 현 시점의 최신 버전인 1.11.3 을 활용하였다. Mariadb Galera Cluster 구현을 위한 준비와 개념도 [Prerequisites] Running k8s cluster with persistent storage(glusterfs or nfs .. 더보기 [Kubernetes ingress part-1] Nginx ingress 구현과 사용 방법 K8s(쿠버네티스) 클러스터 내에 구현된 Application을 외부로 노출하여 서비스할 경우에 주로 Nginx의 LB 기능을 이용한 Ingress Load Balancer를 사용하게 된다. 기본적으로 제공되는 이러한 Nginx 컨테이너 방식 외에도 Haproxy, Traefik Ingress등의 3rd party 솔루션들이 존재하는데, 다음 part-2 에서는 최근 hot하게 뜨고 있는 Traefik Ingress를 사용한 구현을 다룰 예정이다. 필요 요소와 서비스 구성 Kubernetes Cluster(Local cluster, minikube or dind-cluster not in the cloud like AWS or GCP)Backend Service(like web or specific ap.. 더보기 [Kubernetes] 1.7.x~1.9.x, kubeadm 으로 L3 네트워크 기반 Cluster 구성(with Calico CNI)-3/4 4개의 시리즈 중 세 번 째로, 이번에는 2017/08 최종 버전인 Kubernetes 1.7.4 의 kubeadm 을 통한 클러스터 구축을 서로 다른 네트워크가 L3로 연결된 환경에서 구현하는 과정과 방법에 대해 알아 보고, 기본적 테스트와 검증을 진행하는 내용으로 마무리 하고자 한다.* 1.8.x 버전 릴리즈 시 변경 사항 추가(2017.10.16. ... #1.8.x, 붉은 글씨로 표시). : https://github.com/kubernetes/kubernetes/issues/53333 참고)* 1.9.x 버전 릴리즈 시 변경 사항 추가(2017.12.26. ... #1.9.x, 붉은 글씨로 표시). 각 노드에 해당하는 서버의 준비 Master: CentOS 7.3(1611), CPU 2, Mem.. 더보기 [Kubernetes] CentOS 7.3 으로 Kubernetes Cluster 구성(with Flannel)-1/4 Kubernetes 를 CentOS 7 에서 설치하는 방법을 정리해 둔다. 3개의 VM을 준비하고, Mater 하나와 두 개의 Minion(Slave 또는 worker node, 그냥 노드라고도 한다) 구성의 Custer를 구현하되, 네트워크 백엔드 솔루션(Network Fabric)은 CoreOS 에서 기본 채택하고 있는 Flannel을 사용하여 서로 다른 호스트(Worker node, Minion)의 컨테이너간 터널링을 통한 연결이 가능하게 설정할 것이다(총 4개의 시리즈로, 마지막 포스팅에서는 Kubeadm 을 통해, BGP 라우팅이 가능한 Calico Network를 적용한 Kubernetes 클러스터를 구현해볼 예정이다) Docker Engine과 함께 Kubernetes 를 설치하는 방법은, .. 더보기 이전 1 다음