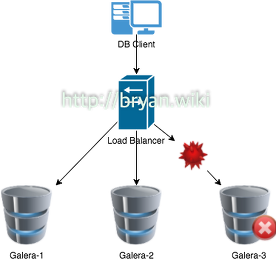
Technical/OS, Infra 썸네일형 리스트형 Split Brain - MariaDB Galera Cluster Case Split Brain 은 Clustering 또는 다중 노드/스토리지 구성의 각종 솔루션들(주로 고가용성과 부하분산, 즉 HA 용도), 예를 들어 Redis-Sentinel, MariaDB Galera Cluster, GlusterFS 파일 분산복제 설정, Oracle RAC, vSphere HA 구성 등에서 중요한 장애 유발 요인이며, Production 환경에서 점검해야 할 중요한 아키텍처적 회피 대상 항목에 해당한다. 1. Split Brain 이 도대체 무엇일까? 문자 그대로 "뇌가 양쪽으로 분단 된" 모양 또는 상황 그자체를 표현한다. IT와 무관한 비유를 해 보자면, 머리 둘 달린 용이 왼쪽으로 갈지 오른쪽으로 갈지 몰라서 갈팡질팡하는 형국이라고 할 수도 있겠다. 실제로 인간의 뇌는 좌뇌와 우.. 더보기 [CentOS 7] Gluster Geo-replication 환경 구축과 테스트 Gluster 파일시스템의 Geo-replication 환경을 구축하고 테스트 하는 과정을 정리해 보자. 작업 환경을 단순하게, 과정을 직관적으로 표현하기 위해 추가 디스크 없는 VM 2개만으로 모든 내용을 소화해 보기로 한다. 이를 위해 Linux 의 Sparse 파일을 가상 디스크로 매핑하여, 마치 추가 디스크가 장착된, 또는 별도 파티션 된 물리 디스크 볼륨이 있는 것처럼 흉내 내는 방법을 같이 다루어 보고자 한다(블록디바이스를 통한 비슷한 테스트를 진행해야 할 때 유용한 방법으로 써먹을 수 있을 것이다). CentOS 7.2에 Gluster Filesystem 설치 먼저 위의 그림과 같이 네트워크가 연결된 2개의 가상머신을 준비한다(CentOS 7.2 또는 RHEL 7.2는 이미 설치되었다고 가정.. 더보기 GlusterFS 3.2.2 - CentOS client에서 Gluster Volume 마운트 하기 (참고)Opensuse 에서는 본 과정이 필요하지 않았음. CentOS에서 별도로 ctype의 설정이 필요한 것을 보면 RHEL 등의 redhad 계열에서 모두 필요한 과정으로 보임. Dependancy: fuse, fuse-devel, flex, bison, python-devel, ctype 위의 의존성 있는 패키지들을 모두 설치하여야 한다. 단, ctype은 기본 centOS repository 에 포함되어 있지 않으므로 Source로 다운로드해서 빌드한다. # wget wget http://downloads.sourceforge.net/project/ctypes/ctypes/1.0.2/ctypes-1.0.2.tar.gz # tar xvzf ctypes-1.0.2.tar.gz # cd ctypes-.. 더보기 Opensuse 11.4 scim을 버리고 nabi 0.99.9 로 갈아타기 * 본 정보는 Opensuse 12.1 에도 그대로 적용 가능하다.Opensuse 에 기본으로 제공되는 scim(xim)은 terminal 에서 한글 입력이 거의 안된다. 무슨 말인지 모르겠다면 직접 설치해서 gedit 이나 chrome 에서 한글을 입력해 보면 된다. 아마도 '우리는' 이라고 치면 '우루는' 이라고 입력되는 꼬락서니를 볼 수 있을 것이다. * 선행 패키지 설치(su - 로 root 로 변신) # zypper in -y gcc make autoconf libhangul libhangul-devel -> http://code.google.com/p/libhangul/downloads/list 에서 libhangul 최신 버전 확인 -> wget http://libhangul.googleco.. 더보기 Linux에서 부트시 스크립트 자동실행 설정하기 이 부분을 이해 하려면 Unix의 RunLevel에 대해 알아야 한다. 기본적으로 Unix 계열의 OS는 아래의 7개 모드로 구분된 Run level을 가진다 0 - Halt status 1 - Single User 2 - Multi User, No Networking 3 - Multi User, Full Networking 4 - Reserved 5 - 3 & X windows 6 - Restarting status 위 각각의 상태로 시스템이 전환될 때 자동적으로 /etc/rc.d/rc?.d/ 의 스타일로 7개의 서브 dir 이 준비되어 있고 각각의 디렉토리내에는 S??scriptname, K??scriptname 형태의 파일들이 존재하는데 S는 start, K는 kil, ??의 숫자는 해당 모드로 진.. 더보기 Windows 7에서 Mac OS X Snow Leopard 설치(Not Hackintosh) 테스트 기종: Sony Vaio Z46/LD 필요조건: VMware 7.0 worksation 설치, System Bios에서 VT를 enable(사전에 최신 VT 지원 bios patch), Internet 연결 사전 다운로드 필요파일들 - h-sl106.iso(약 7.5 G) 더보기 Ubuntu 9.10 vmware tools 설치하기 VMware 7에서 Guest OS로 Ubuntu 9.10을 설치하고 난 후 깔끔한 desktop의 동작을 위해 vmware tools를 설치해야 하는데, vmware에서 easy install을 선택하면 vmware내의 메뉴를 통해서는 toos가 설치가 되지 않는군... ㅡ_-;; vmware tools가 설치되기 위한 개발 환경 설정이 필요하다 > sudo apt-get install build-essential linux-headers-`uname -r` psmisc ctrl+alt 하여 이제 VMware 메뉴의 VM>Re-install Vmware tools 메뉴를 선택하면 Ubuntu 바탕화면에 DVD 아이콘이 설치되고 파일찾아보기 팝업창이 뜨게 된다. 여기서 VMwareTools-***.tar.. 더보기 Ubuntu 9.10 한글 문제 - nabi 기본으로 설치되는 iBUS는 문제가 있어서 여러 해결 방법들이 있지만 Simple is the best 라고 했던가... nabi를 설치하고 입력 인터페이스 패키지로 지정하면 된다 nabi 가 설치 되지 않은 경우에 대비해서 다운로드/설치를 수행한다 > sudo apt-get install nabi 성공적으로 설치되었거나 이미 설치되었다고 나오거나 둘 중 하나일 것이다 다음으로 입력 패키지를 지정한다 > sudo im-switch -c System wide default for ko_KR locale is marked with [+]. There are 2 choices for the alternative xinput-ko_KR (providing /etc/X11/xinit/xinput.d/ko_KR)... 더보기 이전 1 다음