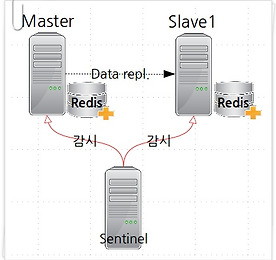
Technical/Development 썸네일형 리스트형 Setting GOPATH & Basic golang 개발 Setting GOPATH & Basic golang 개발 Refer 1: SettingGOPATH · golang/go Wiki · GitHub Refer 2: Go 코드를 작성하는 방법 · golang-kr/golang-doc Wiki · GitHub 특별히 공유 목적을 위해 만든 글은 아니다. 그냥 예전에 했던 설정 방식이 기억 나지 않아 구글링을 하다가 리프레시해둬야 겠다는 단순한 의도로 끄적 거려 둠. 그러나 누군가에겐 조금의 도움이 되었기를 ... Zsh Add to ~/.zshrc export GOPATH=$HOME/go source it source ~/.zshrc Bash Add to ~/.bash_profile export GOPATH=$HOME/go source it source ~/.. 더보기 [GitLab] Server-Side Hook 스크립트(pre-receive) 활용 개요 GitLab 을 위한 Custom Hook은 다음의 3 가지 중 하나로 구현된다(Community Edition 기준). pre-receive: Git 서버가 클라이언트로부터 Push 요청을 받은 즉시 수행되며, 스크립트에서 non-zero 값을 return 하면 Push 요청은 reject 된다. Push 요청에 대한 값은 스크립트 내에서 stdin 스트림 값을 읽어서 사용 가능하다update: pre-receive 와 유사하지만, pre-receive 는 한 번의 Push에 대해 단 한 번 수행되며, update는 각각의 Branch 마다 triggering 되는 점이 다르다. 따라서 여러 Branch에 Push 를 수행하게 되면 특정한 브랜치에 대해서만 reject 되게 처리되게 하고 싶을 떄.. 더보기 Curl로 새로운 GitHub 프로젝트(repository) 쉽게 생성하기 GitHub 에 새로운 repository를 생성할 때 어떻게 하시나요? 주로 github 접속/로그인-New Repository 클릭-이름입력-Create Repository 클릭-로컬 git 디렉토리 생성-git init-git add-commit-push 과정을 통해서 진행할텐데, 과정 자체가 어려운 건 아니지만 번거로운 점이 적지 않습니다. 이 과정을 간단한 스크립트를 만들어서 진행하면 어떨까요? 준비사항GitHub Account: github.com 에 가입(It's free!)Git client와 curl이 설치된 linux box 스크립트 작성 & 실행 여기서 개발자의 작업 PC는 CentOs/RedHat linux 박스로 하고, 우선 Github에 올릴 소스 작업 디렉토리가 필요하겠지요. .. 더보기 [Kubernetes, Docker] Go 언어로 Tiny Web Server 만들고 docker hub에 공유하기 최근 Containter Orchestration 관련된 작업을 진행하고 있는데, 초기 테스트 수준의 클러스터 구성이나 솔루션의 기능 확인/검증시에 사용할 Web Server 기능을 하는 컨테이너를 주로 nginx 베이스 이미지를 사용 하고 있는데, 특정 용도에 맞게 html 파일을 수정해 주어야 하는 등 귀찮은 일 들이 많다. 도커 이미지 크기도 100MB 이상이어서 생각보다 크고... 그래서 생각한 것이 "내 맘대로 주무를 수 있는 컨테이너형 작은 웹서버" 를 만들고 언제든 사용할 수 있게 해 보자는 생각이 들었다. 어떻게 하면 작고 가벼운 웹서버를 만들고 필요할 때 언제든 사용할 수 있는가? 베이스 이미지가 작아야 하므로 busybox 이미지를 쓴다(1 MB +) 웹서버의 하위 페이지에 따라 특정 .. 더보기 [Mac/Xcode] git repository 와 연동해서 코딩하기 Mac OSX 에는 Xcode 라는 좋은 무료 개발도구가 있다. 물론 Mac 에서도 CodeLite, CodeBlocks 와 같은 잘 알려진 오픈소스 개발도구를 쓸 수 있지만, Codeblocks 는 Mac OSX 에서의 안정성이 떨어지는 감이 있고 CodeLite 는 Mac 에서 command-line 프로그램 개발 시 iostream 의 cin 을 제대로 처리 못하는 등 조금씩 문제를 안고 있기 때문에 쓰다 보면 불편함이 쌓이게 되고, 그러다 보니 Apple 에서 Mac 을 가장 잘 지원해 주(는 것으로 믿고 싶은...)는 Xcode 같은 Native app으로 다시 돌아가곤 한다. 이번 글에서는 Xcode 로 C++, Objective-C, Swift 와 같은 언어를 사용한 개발에 있어서, 협업 개.. 더보기 [Linux/Bash script] EUC-KR 로 된 한글 smi 자막을 UTF8 srt 로 변환하기 소장하고 싶은 영화나 동영상 파일들을 모아서 디스크 한 켠에 폴더별로 잘 정리해서 보관하는 경우가 많다. 그렇다고 자주 들춰보기는 쉽지 않지만, 일종의 "혹시나 다음에 또 보고 싶어질지도 몰라...ㅋ" 하는 미련 같은 건 아닐까(그러다 결국 한 순간에 폴더째 지워버리게 되기도 하지만...ㅠㅠ). 아, 위에 나오는 짤방성 이미지의 context sensitive한 자막은 참 공감이 많이 가고, 무엇보다 푸근한 처자에게 고맙다(뭐가 ? ^^;;). 2016년 첫 포스팅 치고는 거의 솔플메모에 가까울 정도로 가볍다. 언제나 심각하고 거창할 순 없는 거다. 각설하고, 이제 본론인 메모 작성으로 넘어가자. Handbrake로 동영상을 변환 다운로드 받은 영화를 보관 또는 거실TV에서 상영하기 전에 거실 PC의 L.. 더보기 [프로그래밍] stackOverflow - 2줄 짜리 질문에 대한 명답 of 명답 [스택오버플로우] 2줄 짜리 단순한 질문에 대한 명료한 분석과 이유를 달아준 명답 of 명답. 지난 5월에 올라온 이슈답변에 이 시간 현재 평점 38만 점, 황금배지 54개!☞보러 가기 짧고 격하게 공감하고 오래 기억하라 단순한 따라하기 보다는. 왜 그래야 하는지 알려고 노력하는 것이 얼마나 중요한지 새삼 깨닫게 해 준다.비단 C++코딩에서 뿐이랴. 특히 과학을 하는 이에게 원리와 이유의 탐구가 얼마나 중요한가 말이다. 그러니 늘, 기본에 충실하라. 이건 나 자신에게 하는 말. * RAII 는 Resource Acquisition IS Initialization 이라는 표현의 약어로 C++을 창시한 Bjarne Stroustrup 이 주장하는 일종의 기술적 원칙이다. [스택오버플로우] 2줄 짜리 단순한 .. 더보기 [프로그래밍] Fizzbuzz 문제에 대하여(2) 지난 포스팅의 마지막에 Fizzbuzz 를 풀어 내는 희한한 예제를 게시한 바 있습니다. 좀 오래 되긴 했지만, 궁금해 하는 후배가 있어 한 번 같이 분석해 보았고 독특하고 엉뚱한 생각에 재미를 조금 느끼기도 했습니다. 실제 인터뷰시의 사례인지는 알 수 없지만, 이 해법을 소개한 페이지(Fizzbuzz 에 지겨워진 개발자들)을 잠깐 보면, "일단 똑똑하다", "뽑고 싶다" 거나 "생각이 한쪽으로 쏠린 사람", "팀웍을 해칠 것 같다" 는 등의 다양한 반응를 예로 들고 있네요. 글 쓴이(Samuel Tardieu) 자신은 일을 하면서 이런 식의 재미를 추구하는 방식을 좋아한다고 적고 있기도 합니다. 여러분은 어떠신가요? 우선, 소개된 원본 소스를 그대로 두고 한 번 훑어 보기로 합니다. 참, 한 번 실행시.. 더보기 [프로그래밍] Fizzbuzz 문제에 대하여(1) Fizzbuzz(피즈버즈) 문제. 프로그래머라면 한 번 쯤 풀어 보거나 들어본 경험이 있을지도 모르겠다. 만약 프로그래머로서의 직업을 가지려고 하거나, 단순한 취미로라도 "나 프로그램 좀 짠다" 라는 말을 할 수 있으려면 꼭 접해 보았어야할 문제다. 만약 Fizzbuzz 문제를 처음 듣거나, 예전에 들었는데 가물가물한다...하는 분이라면 이참에, 다시 한 번 스스로를 돌아보는 계기를 마련해 보자. 이건 글을 쓰는 본인에게도 해당하는 말이 될게다. Solid programming이나 Grok coding는 수 많은 고민과 노력에 의해 충분히 만들어 질 수 있다고 나는 믿는다. 중요한 건 엔지니어로서의 동기, 자부심 또는 열정 아니겠는가? Fizzbuzz 문제가 뭐임? "Fizzbuzz questions"는.. 더보기 [GIT TIP] git 서버인 AWS EC2 VM의 주소가 바뀌었을 때 개인용 wiki 사이트, git 서버용으로 쓰던 Amazon EC2 vm에 고정 ip인 소위 Elastic IP를 물리고 인터넷 도메인(doubleshot.io)을 할당해서 쓰고 있다. git 서버의 접속 주소가 바뀌었으니 당연히 그에 맞게 git 의 remote 설정을 바꿔야 해서, 그 과정을 샘플 노트 형태로 작성해 둔다. * git repository 에 해당하는 디렉토리(MyCppProjects)로 이동하여 변경 이전의 접속 주소를 "git remote" 로 확인* 접속 방식은 기존 pem 인증키를 이용한 ssh 방식이므로 .git/config 파일의 접속주소 중 도메인 부분을 새로운 도메인(doubleshot.io)으로 교체하고 저장✔ ~/MyCppProjects [master L|✔] 22:1.. 더보기 [Git Tip] git를 위한 GUI browser, ungit 설치와 node.js 소스 빌드 ungit은 git 사용자를 위한 유용한 GUI 브라우저이다. ungit 은 node.js 상에서 동작하므로 이참에 node.js 를 source로부터 build하고 ungit 을 설치하는 과정을 메모해 둔다. 1. tarball 소스로부터 node.js 빌드 & 설치 bryan@bryan-laptop1:~/Downloads$ wget https://nodejs.org/dist/v0.12.7/node-v0.12.7.tar.gzbryan@bryan-laptop1:~/Downloads$ sudo apt-get install build-essential python-devbryan@bryan-laptop1:~/Downloads$ tar xvzf node-v0.12.7.tar.gzbryan@bryan-lapto.. 더보기 [Git Tip] Git Branch와 상태를 보여주는 Linux Prompt(bash-git-prompt) 지난 번 Git 을 위한 Linux Prompt 변경 내용에 추가하여, Github.com 프로젝트 중에서 쓸만 한 것이 있어서 소개해 두도록 한다. 단순히 Branch 명을 보여 주는 것에서 벗어나서 브랜치의 자세한 상태까지 Prompt 에서 보여 주므로 아주 실속 있는 Git용 프람프트 유틸리티가 아닐까 한다. 설치 과정도 아주 간단하여 쉽게 적용해 볼 수 있다. * 적용 대상: Bash를 사용하는 Linux 또는 Mac * 설치 방법: https://github.com/magicmonty/bash-git-prompt 에 있는 내용 참조 * 설치 과정(Ubuntu 14.04, Bash 사용)bryan@bryan-XenPC:~$ cd ~ bryan@bryan-XenPC:~$ git clone https.. 더보기 [Git Tip] Git 브랜치를 보여주는 Linux 프람프트(prompt) - Ubuntu 14.04, bash 기준 Git을 사용하는 방식은 명령형(커맨드라인; Command line; 또는 터미널 방식) 이거나 GUI Client 형(Mac, Windows)이거나 둘 중 하나일 것이다. Git의 내부 메커니즘을 알기 위해서이기도 하지만 커맨드라인 방식이 익숙해 지면 훨씬 수월해 지는 경우가 많은 듯 하다. 이 때 어쩔 수 없이 git status 를 쳐서 현재 어떤 브랜치에서 작업중인지를 수시로 확인해야 하는데, Linux 의 프람프트를 개조해서 사용하면 편리한 점이 많으므로 그 방법을 정리한다. "Git 은 브랜치로 시작해서 브랜치로 울고 웃다가 브랜치로 끝난다" - Barracuda - * 준비물: github 에서 공개된 아래의 스크립트를 계정의 Home에 내려 받아 둔다* git-prompt.sh 는 Bash.. 더보기 [Git Tip] Git에 대한 궁금증들 Git 을 다루는 엔지니어들이 점점 늘고 있다. 한글 입력상태에서 자판으로 git을 치면 '햣' 이 된다, 햣~! 너도 나도 써야한다라고 하니, 이게 마치 무슨 대세가 된 건 아닌가 착각도 하게 되는데, 막상 써보려니 손에 익고 간편한 cvs, svn 과는 비슷하면서도 뭔가 좀 다르고 어렵기도 하다. 근데, 간편안내서 같은 곳을 보면 "어렵지 않아요 ;)" 하면서 사람을 막 꼬드긴다(가서 보면 더 너무 쉽게 써놔서 더 아리송하다). 그게 대체 뭐길래...하면서 약도 좀 오르고 궁금하기도 하다. 이제, 하나 하나 따져가면서 왜 그런가 고민하고 정리해 두는 버릇이 있는 필자가 git을 한 번 다루어 보려 한다. Git을 써야 하는 이유 결론부터 간단히 말하자면, Git 은 약간의 개념공부와 실습이 필요한 T.. 더보기 [Git Tip] AWS EC2 VM을 이용한 Git 서버설정과 git 기본 사용법 git(깃) 서버를 Amazon EC2 인스턴스에 설치하고, Repo를 운영 관리하는 기초과정 정리 * 준비해야 할 것들 - 서버: AWS EC2 t2.micro, ubuntu 14.4, 접속주소: ec2-xx.amazonaws.com - 클라이언트: Ubuntu 14.4 PC, EC2 vm ssh 접속을 위한 보안 키파일(여기서는 AWSKP_as1.pem) EC2 vm측, git 서버 설치 과정 * 필수 패키지 설치root@aws-ubt14-as01:~# apt-get install git-coreroot@aws-ubt14-as01:~# apt-get install openssh-server * linux 계정(=gituser) 추가, 권한 설정 및 key pair 생성* 이 방법은 git 계정을 공용.. 더보기 Redis, Sentinel 고가용성(HA) 설정과 운용방법, Python Client example Redis(레디스; REmote DIctionary System)은 요즘 각광 받고 있는 In-memory Data(key-value) Store이다. 언제고 한 번 다뤄 봤으면 했는데, 마침 비슷한 기회가 주어져서 고가용성을 확보할 수 있는 중요한 설정 방법을 찾아보고 Redis 를 활용하는 아주 간단한 Python Client 예제를 정리하여 실전을 위해 기록해 두고자 한다. "쓰다 보니 내용이 좀 많습니다. 2편 정도로 나누려 했으나, 다루려고 하는 내용을 한 편에 모아서 구성하는 편이 더 좋다고 생각했으니 스크롤 압박이 심하더라도 양해 바랍니다" - Barracuda - "Redis 는 DBMS 인가?", "임시 데이터 저장용 캐시라고도 하던데..." 하는 잡다한 얘기는 여기서는 생략하자. 자주 .. 더보기 Python GUI 프로그래밍을 위한 PySide 1.2.2, Linux/Windows 에 설치하기 Python을 활용한 GUI 프로그래밍에 꼭 한 번씩 거론되는 것이 있다. 오픈소스 프로젝트로서, Python을 위한 C++바인딩인 PySide 프로젝트가 그것이다. 참고로, 기존의 PyQt4에는 API Level 1과 API level 2 가 각각 존재하고 있으며, 그에 비해 PySide는 PyQt API level 2 만을 고려하여 구현되어 있다(PySide 쪽이 LGPL이 적용되어 PyQt 보다 저작권 면에서 더 자유롭다...정도만 얘기하고, Qt의 역사나 핀란드의 노키아, 디지아 등 잡다한 궁금한 점들은 구글링으로 해결하자). 서두가 너무 길었다. 간단히 글 게재의 목적만 말하자면, PySide 1.2.1 버전은 대다수 리눅스 배포판 등의 소프트웨어 다운&설치 명령들(yum, zypper, apt.. 더보기 Linux OpenSUSE 13.* 에서 Pycharm 사용하기 : update-alternatives 활용 OpenSUSE 13.2 에서 python 개발환경을 구성할 경우에 거쳐가야 할 몇 가지 단계들이 있다. 아마도 대다수 OpenJDK를 채택한 Linux들에도 해당될 듯 한데, Pycharm이 Linux를 위한 구현을 java 로 하였기 때문에 발생하는 일종의 패키지 충돌 문제를 만나게 된다. 다시 말하면, Opensource 진영에서 채택한 OpenJDK는 OpenSUSE 뿐 아니라 Ubuntu 등 대다수 Open Linux 배포판들이 java 플랫폼을 위해 기본으로 포함하고 있다. 그러나 Linux용 Pycharm은 Oracle-Sun jdk/jre 기반으로 만들어져 있으며, 이 문제는 update-alternatives 라는 유틸리티로 극복할 수 있다. 이를 잘 활용하면, 서로 다른 버전의 gcc가.. 더보기 Python - pysnmp, pymongo, python-mysql 작업 환경(OpenSuse 11.3) 점검 대상 머신에 SNMP를 설정(SNMP agent; server side)하고 python 프로그램(SNMP manager; client side)로 모니터링 데이터를 수집하기 위한 셋업 절차. OpenSuse 11.3 repository 에는 pysnmp가 포함되어 있지 않으며, pymongo 는 OpenSuse 12.* 에서도 공식 지원하지않으므로 수작업으로 설치해야 한다(python 2.6.5 기준) * pysnmp : python 환경에서 NET-SNMP Agent/Manager 개발시에 필요한 API* pymongo : python 환경에서 mongodb 관련 application 개발시에 필요한 API/driver [Client - pysnmp 설치]# zypper in -y python-.. 더보기 PHP5 + lighttpd fastcgi + mongodb + mysql(openeuse 12.1) 개발/운영 환경 설정 Opensuse 12.1 환경에서 PHP5 + lighttpd fastcgi + mongodb + mysql 개발/운영 환경 설정* howtoforge.com 내용 참조, 테스트 실행 & 보완 1. Lighttpd & php5 환경 설정 # zypper in -y lighttpd# systemctl enable lighttpd.service# systemctl start lighttpd.service * 기존의 php5 fastcgi 가 php5-fpm 패키지로 통합 업그레이드 되었고 별도 daemon으로 동작한다.# zypper in -y php5-fpm # mv /etc/php5/fpm/php-fpm.conf.default /etc/php5/fpm/php-fpm.conf# chmod 1733 /var.. 더보기 PHP5 + lighttpd fastcgi + mongodb + mysql(openeuse 11.3) 개발/운영 환경 설정 Opensuse 11.3, 12.1 각각에 대해 2회에 걸쳐서 정리* howtoforge.com 내용 참조, 테스트 실행 & 보완 1. Lighttpd & php5 환경 설정 # zypper in -y lighttpd# chkconfig --add lighttpd# chkconfig lighttpd on# service lighttpd start # zypper in -y php5-fastcgi * 아래 라인을 찾아서 un-comment# vi /etc/php5/fastcgi/php.ini cgi.fix_pathinfo=1 * 아래 라인을 찾아서 un-comment# vi /etc/lighttpd/modules.confinclude "conf.d/fastcgi.conf" server.modules = (.. 더보기 날짜 데이터를 찾는 Perl 정규식 데이터 마이그레이션 등 작업시 날짜 데이터 부분, 즉 '2011-08-23 11:24:56' 으로 된 부분만 찾아서 now 와 같은 것으로 바꿀 필요가 가끔 있을 때 요긴하다. '[12][0-9]{3}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01]) [0-2][0-9]:[0-5][0-9]:[0-5][0-9]' 년도: 1 또는 2로 시작하여 0 ~ 9 사이의 값으로 3자리가 채워지며,월: (0으로 시작하는 경우 뒤에 1~9 사이의 값) 또는 (1로 시작하는 경우 뒤에 0~2사이의 값),일: (0으로 시작하는 경우 뒤에 1~9 사이의 값) 또는 (1또는 2로 시작하는 경우 뒤에 0~9사이의 값) 또는 (3으로 시작하는 경우 뒤에 0 또는 1)... 더보기 Linux cvs repository 복구 왠지 모르게 cvs의 설정과 복구과정에 대해 헛갈려 하는 cvs 사용자들을 위해 작성 cvs 서버의 장애로 1. 새로운 머신에 cvs server를 설치하고 2. repository를 초기화 한 후 3. Local PC의 최종버전의 파일들을 밀어 넣는 방법으로 복구하는 과정이다 1. cvs server 설치(root) # apt-get install cvs cvsd xinetd openssl ubuntu가 아닌 Suse, Centos(or Fedora)는 zypper, yum 등을 통해서 설치 # groupadd cvsgrp # useradd -M -g cvsgrp -s /bin/false cvs 2. Repository 초기화 # mkdir /home/cvs # cvs -d /home/cvs init .. 더보기 Lightweigh DB - Linux에서 MongoDB c++ 어플리케이션 개발하기 개발도구는 Sun Studio 12.1 로 해 보자(NetBeans 6.8도 가능) 개발을 위한 컴파일러는 gcc 4.1* 이상이어야 한다. 우선 mongoDB 다운로드 & 설치 - www.mongodb.org 에서 mongodb binary 또는 소스를 받아서 설치한다 - 소스 설치시는 의존성에 걸리는 빌드도구들을 여러가지 받아서 설치해야한다. 특히 scons 가 필수인데 Ubuntu, centOS에서는 숫한 삽질을 통해 scons 소스를 컴파일해서 빌드한 기억이 난다. 우여곡절 끝에 mongodb를 다음과 같이 빌드할 수 있다 # scons --prefix /usr/service/mongo install - mongodb 는 rpm 같은 패키징이 없이 tar.gz binary 압축해제/복사 또는 so.. 더보기 CentOS 5.4 Final, MySQL connector c++ 빌드하기 Linux 패키지 종류가 다양하고 Compiler version과 라이브러리 버전이 워낙 다양하므로 MySQL connector c++ 1.0.5 버전 rpm을 설치하면 컴파일시 libstdc++.so.5 버전이 필요한데 libstdc++.so.6 버전이라서 경고가 뜨는 경우가 있다. 대개는 오류가 주루룩 뜨지만, 가끔 경고만 뜨고 컴파일은 되나 실행하면 거의 core가 생긴다. 이 때는 어쩔수 없이 직접 source 로부터 connector c++을 빌드해서 써야한다(아니면 statifier 같은걸 쓸 수도 있지만 편법이라 별로다) 우선 cmake 2.6.2 버전 이상이 필요하다. # wget http://www.cmake.org/files/v2.8/cmake-2.8.0.tar.gz # tar -xvz.. 더보기 Ubuntu 9.10에서 MySQL Connector/C++ 프로그램 개발 NetBeans 6.8 에서 C++을 통하여 MySQL을 다루기 위해 Connector C++을 사용하기로 하였다. 처음부터 쉬운 길을 택한 것에 대한 징벌인가 ㅡ_-;; 샘플 소스 받고 빌드 하니 ld 에서 오류가 떨어진다...엉뚱한 버전의 라이브러리를 찾고 난리도 아니다. Binary 버전(Redhat, SUSE, Max OSX, FreeBSD, Windows 용 다 있는데 Karmic 용은 없네...generic 을 받을 수 밖에...)을 다운로드 받고 tar로 압축 풀고 /usr/include, /usr/lib 에 적당히 복사하고 Library link 정보까지 깔끔하게 업데이트 하기 위해 ldconfig 까지 돌렸는데;;; 안된다. 구글링을 해 보니, MySQL Connector C++ bina.. 더보기 Ubuntu 9.10, eclipse cdt 설치하고 c, c++ 개발하기 CD1장으로 된 Ubuntu desktop 버전은 Linux를 간편하게 사용하게 만들어진 패키지여서 개발툴, 환경, 라이브러리들이 자동으로 설치/설정되지는 않는다. 더구나 Eclipse(Galileo 라는 코드명을 가졌던가...아무튼) cdt는 ubuntu의 synaptic 관리자에서도 더 이상 패키지 설치목록에 뜨지 않게 바뀌어 버렸다. Eclipse cdt(C, C++ Development Toolkit ? ...)을 사용하려면 우선 eclipse 최신 버전을 synaptic 관리자를 통해서 설치한다 (추가로 설치가 필요하다고 마킹된 것들 중에서 pde는 반드시 설치, jde는 java 개발을 하지 않는다면 필요 없을 듯) 다음 eclipse를 실행한 후에 아래의 절차에 따라 설치한다. - Help .. 더보기 Ubuntu 9.10 에 Tomcat6 설치하기 무지하게 심플하다 (물론, 그 전에 설치, 사용을 위한 환경을 체크해야 하지만...) 더 심플한 방법은 synaptic 패키지관리자로 설치하는 방법이지만 대략 흐름을 파악하는데는 수동으로 설치해 보는 것도 도움이 될 것이다. 패키지 다운로드 받고, 압축풀고, 복사해 넣는 과정이다. 우선 java 버전을 확인한다. tomcat을 원활히 동작시키려면 sun의 jdk가 필요하다. > java -version java version "1.6.0_15" Java(TM) SE Runtime Environment (build 1.6.0_15-b03) Java HotSpot(TM) 64-Bit Server VM (build 14.1-b02, mixed mode) 위와 같은 결과가 나오면 더 준비할 게 없지만 만약 op.. 더보기 Java+jdbc+Drizzle Sample code Drizzle은 설치되고 drizzled가 떠 있다고 가정한다 1. 우선 java부터 쓸 수 있도록 환경 구성 > java -version 으로 확인 깔려 있지 않다면 받아서 설치부터 go go(sun java 나 open jdk를 알아서...) sun 버전을 설치한다면 > sudo apt-get install sun-java6-jdk 다른 자바 버전들이 여러개 깔려 있는 경우는 > sudo update-alternatives --config java There are 2 choices for the alternative java(providing /usr/bin/java). Selection Path Priority Status -----------------------------------------.. 더보기 Ubuntu 9.10 karmic에서 drizzle 설치하기 ubuntu에서 drizzle 설치가 의외로 까다로와서, 따로 정리한다. 우선 컴파일에 필요한 아래의 패키지를 다운로드/설치한다 > sudo apt-get install libpcre3-dev libevent-dev autoconf automake bison libtool ncurses-dev libreadline-dev libz-dev g++ libssl-dev uuid-dev libpam0g libpam0g-dev gperf libevent 가 too old 하다고 나올 경우 새 버전을 받아야 한다 > sudo apt-get install libevent-dev libdrizzle, Google protocol buffer가 필요하다, 다운로드/설치한다. >sudo apt-get install lib.. 더보기 이전 1 2 다음